真相永远只有一个!
# 起因
研究生毕设的测试和实验打算再 K8s 集群上进行,于是需要先部署一个 k8s 集群环境。前两周分配了十台虚拟机搭建了一个 3 master + 7 worker 的高可用 K8s 集群,但当时就出现了因为节点 OOM,系统进程被杀死导致节点宕机最后整个集群都崩溃的问题。当时以为是虚拟机内存开太小了,或者是虚拟机使用了网络存储的问题,重装了一遍,然后没有在意。直到这周,沃老师让我在十台物理服务器上部署 k8s 集群,这十台服务器每个都有 188G 内存,结果相同的情况再次出现。于是不得不去寻找集群节点崩溃的真实原因。
# 问题表现
部署好 k8s 集群之后,刚开始一切正常,但每次我部署完 kubesphere 之后,集群部分节点就会处于 NotReady 状态。但这些机器一般还可以通过 ssh 进行连接,我尝试过直接重启这些 NotReady 的节点,但这些节点在刚开机时使用 kubectl get nodes 仍然处于 Ready 状态,可是没过一会儿就又自动掉线了。
# 问题排查
# v1.0
联系能连上远程控制台的 BW 兄,发现了这些节点故障的原因:
节点重启后,查看一下 OOM 日志:
egrep -i -r 'killed process' /var/log
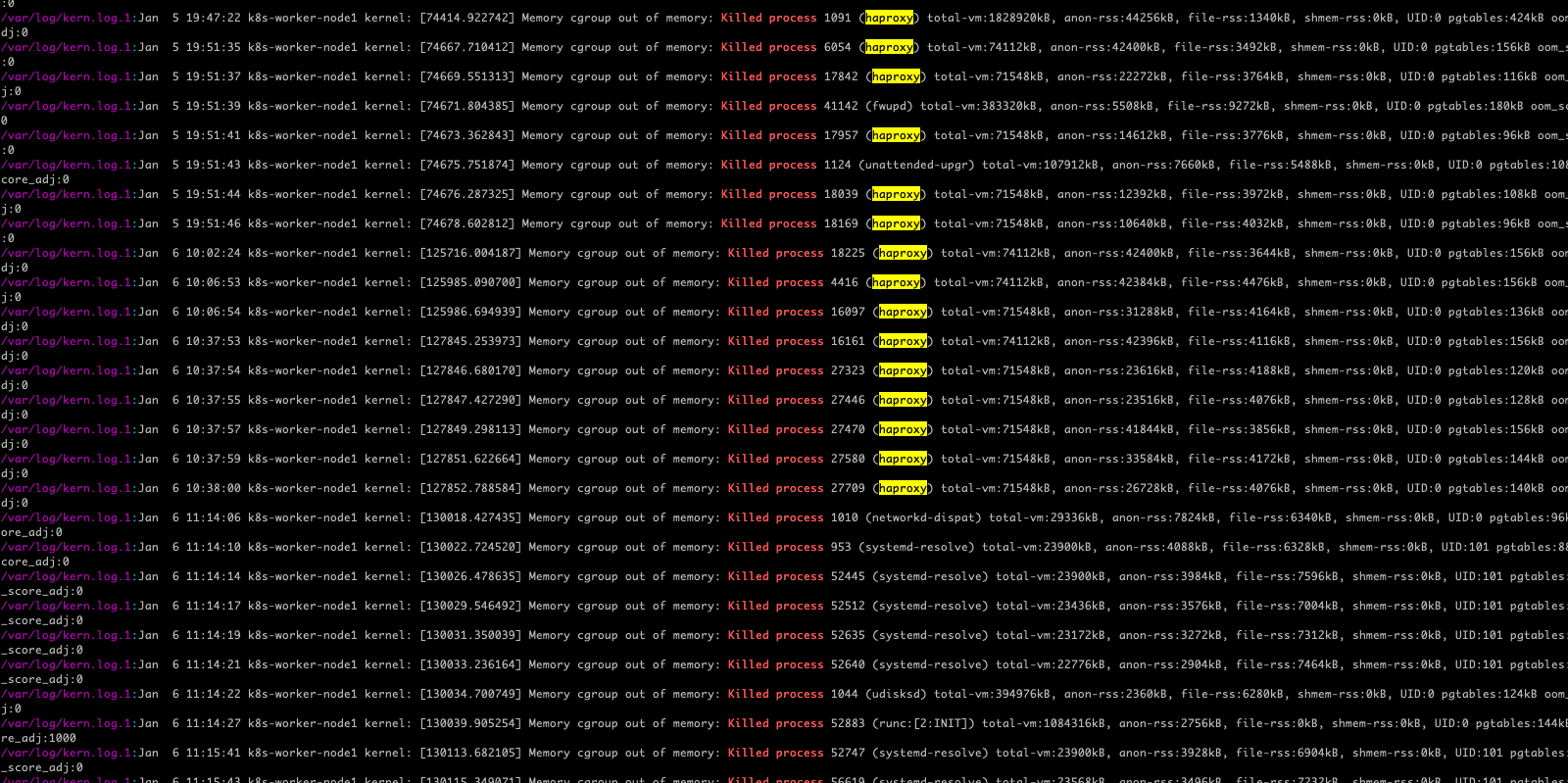
可以看到,大量的系统进程被杀死,k8s 的高可用代理 haproxy 赫然在列。所以,原因找到了!因为我的 haproxy 没有配置对,导致内存占用过大,触发了 OOM,由于 haproxy 挂掉之后,Worker 节点无法连接到 master,从而显示为 NotReady。
# v2.0
问题就这么轻松的解决了?NO!
在尝试修改了多次 haproxy 配置后,worker 节点还是会大量触发 OOM,haproxy 进程仍然频繁被杀死。再仔细看日志,发现 haproxy 被杀掉之前,它内存占用并不大,只有几兆而已。就这点内存居然会被一个 188G 内存的服务器挑出来杀掉,实在不可思议。
后续又发现,每次 haproxy 挂掉的时候,DNS 解析也大概率会挂掉(systemd-resolved),日志里面也提示了 Memory cgroup out of memory。所以,我猜可能是 cgroup 配置的问题,haproxy 所在的 cgroup 内存限制太小了。
我们看看 haproxy 位于哪个 cgroup
systemctl status haproxy
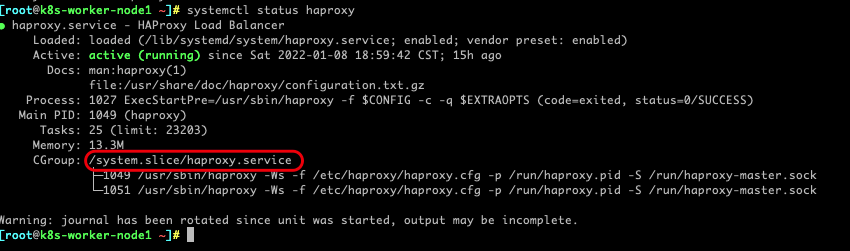
看一下这个 cgroup 的限制
cd /sys/fs/cgroup/memory/system.slice/
cat haproxy.service/memory.limit_in_bytes
2

9223372036854771712 这么大的内存,没啥问题啊。
那只能看看上一级的内存限制了:

536870912 字节!,问题找到了,整个 system.slice 被限制到了 0.5 G ! 我们验证一下:
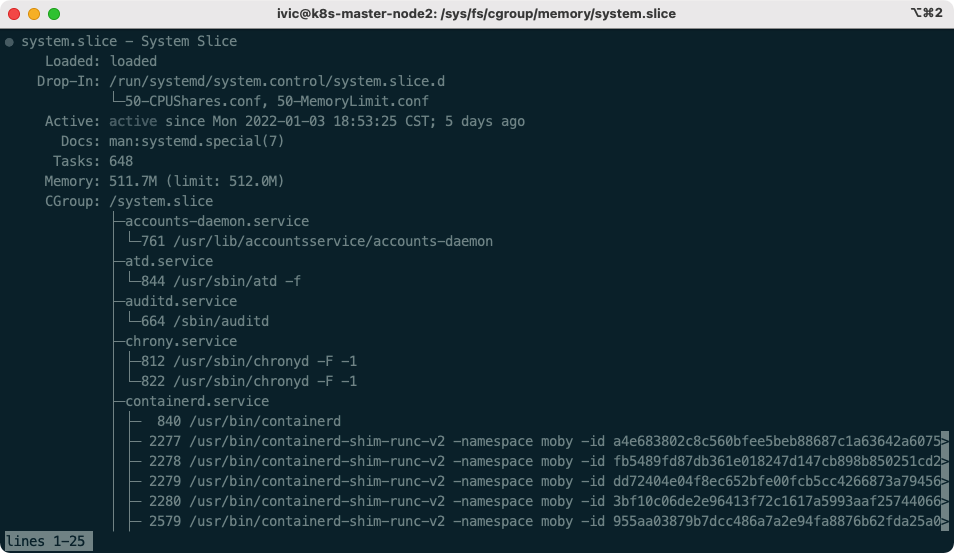
果然!Memory: 511.7M (limit: 512.0M),这么大的内存他不用,把整个系统进程的可用内存限制在了 0.5G,不到整个节点内存的 1/200
尝试修复:
systemctl set-property system.slice CPUShares=1024
systemctl set-property system.slice MemoryLimit=infinity
2
去除了对 system 的 CPU 和内存限制,再看看
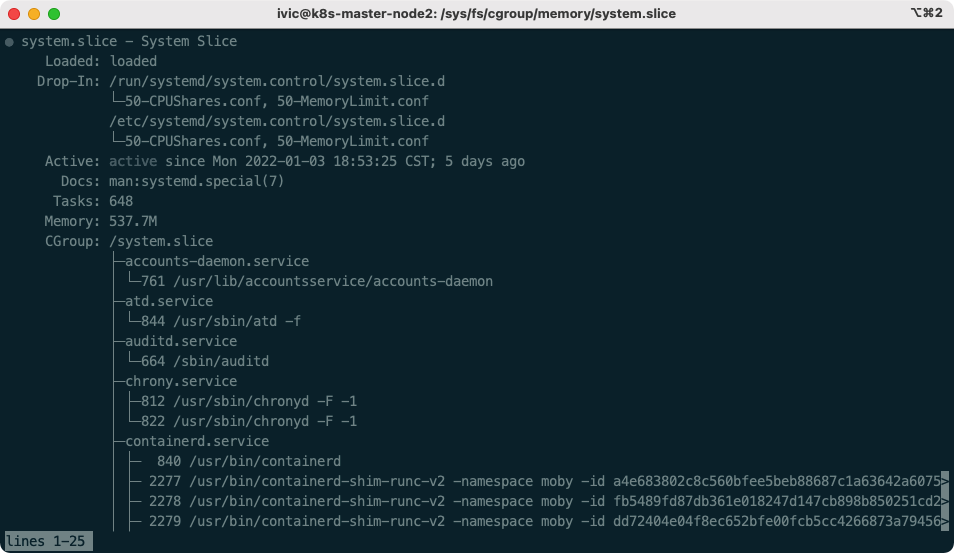
诶,限制没有了,好了!
# v3.0
你以为这就结束了?native!
节点重启之后,system 的可用内存又被重新限制到了 0.5 G,仿佛我所有的努力都没有发生过。
查阅了一些资料,通过 systemctl set-property 设置的配置应该是持久化的,不应该重启失效才对。为了排除是 Ubuntu 20.4 系统本身的问题,我用相同的镜像重装了一个系统,发现系统默认是没有 0.5 G 内存限制的。那一定是在其他的地方偷偷改了我的配置!
会是谁呢?我这个集群只装了 k8s,那一定是配置 k8s 的过程当中导致的。
仔细查找我安装 k8s 的配置和脚本,在一个不起眼的地方发现了一个嫌疑人
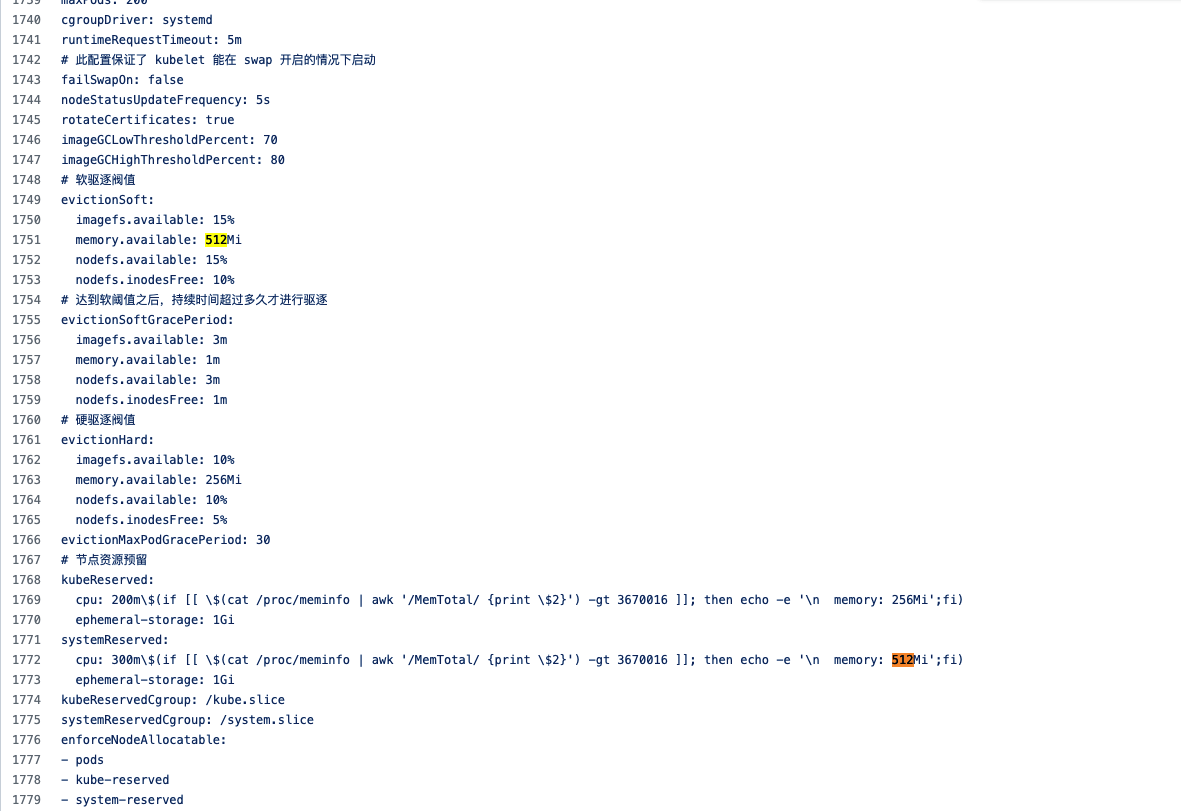
# 节点资源预留
kubeReserved:
cpu: 200m
memory: 256Mi
ephemeral-storage: 1Gi
systemReserved:
cpu: 300m
memory: 512Mi
ephemeral-storage: 1Gi
kubeReservedCgroup: /kube.slice
systemReservedCgroup: /system.slice
2
3
4
5
6
7
8
9
10
11
512M!除了这里,我再也找不到类似的内存限制了,和 system.slice 一起限制的还有 kube.slice,我们也来看看他:
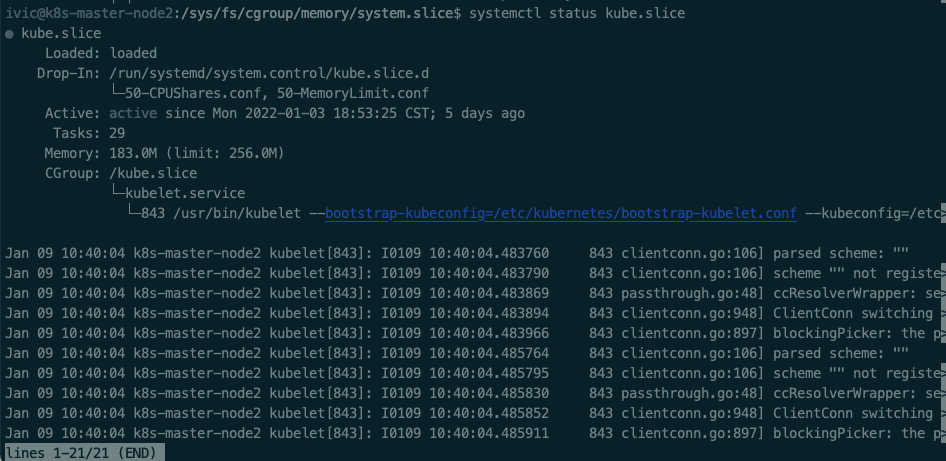
果然 256M!,看到这里,这个嫌疑基本实锤了!让我苦苦寻找了三天的问题,就是他!
但这里 systemReserved 明明看字面意思是资源预留,查询官方文档也是给系统进程预留资源,但为什么变成了资源限制呢?
跟本原因是 enforceNodeAllocatable 这个字段的配置问题。
我理解错了 enforceNodeAllocatable 的意思了,我以为它是开关,实际上是给这几个创建 cgroup。reserved 配置了就会减去分配的配额,它开了就会强制 cgroup 限制 kube 和 systemd 来预留,也是不推荐配置的。取消它的配置为下面相关:
来源:https://zhangguanzhang.github.io/2021/08/16/reserve-compute-resources/#坑 (opens new window)
# 修复
之后,ssh 到每个节点上,修改配置文件:/var/lib/kubelet/config.yaml,将 kube-reserved、system-reserved 从 enforceNodeAllocatable 中删除:
enforceNodeAllocatable:
- pods
# - kube-reserved
# - system-reserved
2
3
4
修改之后需要重启节点,方可解除内存限制。
至此,问题解决